
I Know Kung Fu
How My AI Metabolizes Anything
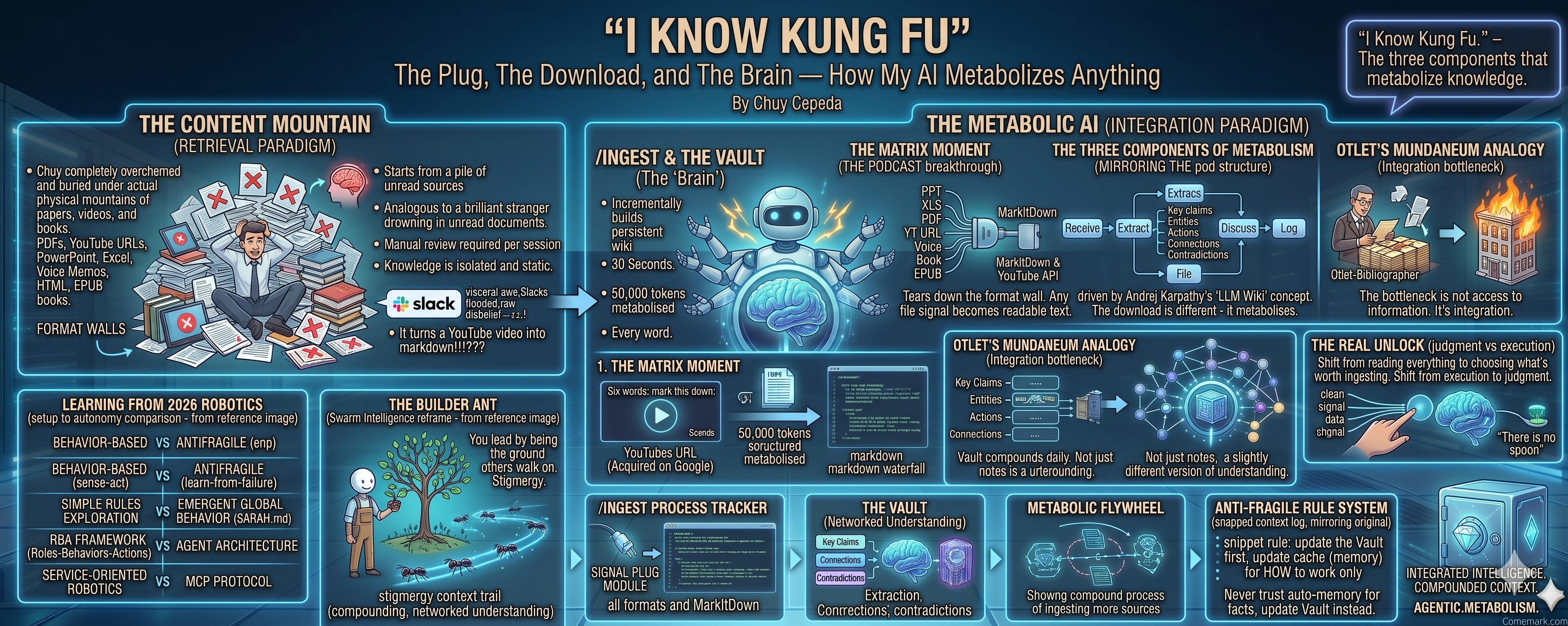
There’s a scene in The Matrix everyone remembers. Neo sits in a chair. A plug goes into the back of his skull. A cascade of martial arts training data floods his brain. He opens his eyes, looks at Morpheus, and says four words:
“I know kung fu.”
Three things had to happen for that moment to work. The plug had to connect. The download had to transfer. And the brain had to integrate it — not just store it, but make it usable. Miss any one of those three and Neo wakes up with a headache instead of a roundhouse kick.
Last night, I watched the same three things happen to my AI.
The moment
I’ve been building what I call an AI Operating System — an Obsidian vault wired to Claude Code with commands, context layers, and a daily rhythm that compounds over time. If you’ve been following this series, you know the building blocks: one file that tells the AI who you are. One architecture that lets it remember. One fortress that keeps it running overnight.
But last night I tested something I hadn’t pushed to its limits before. I threw it a ~12-hour, 3-episode podcast series. Acquired’s deep dive on Google — Origins of Search, Alphabet, and The AI Company. Nearly twelve hours of dense, narrative-driven content.
I typed three words: mark this down: and pasted YouTube URLs.
10.6 seconds later, I had the full transcripts. Every word. 154,526 tokens. Metadata, descriptions, timestamps, links — all intact. Thirty strategic insights extracted across the three episodes — Google’s innovator’s dilemma, the Rosewood dinner that peeled Ilya Sutskever off to OpenAI, the Transformer paper described by Acquired’s Ben Gilbert as “the greatest gift to humanity / worst decision for Google.” Then the system metabolized everything, identified connections to existing files, flagged where new information contradicted or enriched existing notes, and presented a structured filing plan — with cross-references to vault notes I’d written months ago that I’d forgotten about.
A roundhouse kick.
I want to be honest about what happened next: I cried. Not the composed, intellectual kind of awe. The visceral kind. The kind where your chest tightens and you need a second before you can type. I dropped into our team Slack and just started flooding the channel — half sentences, all caps, raw disbelief.
Diego responded in seconds:
“It turns a YouTube video into markdown!!!???”
Three question marks and three exclamation points. He got it instantly.
What happened on my screen was the same three-part sequence from the Matrix. A plug connected to the source. A download metabolized the knowledge. And a brain integrated it into everything it already knew.
Here’s how each part works.
The plug
Before you can download anything, you need to plug in. And the problem my system had before last night was simple: it could only eat what it could read.
Articles and markdown files — easy. That’s the AI’s native tongue: plain text, no wrapper, no parsing tax. PDFs — possible with extraction tools. But the real knowledge in the world doesn’t live in markdown. It lives in PowerPoint decks from board meetings. In Excel spreadsheets from financial models. In voice memos from walks. In infinite minutes of YouTube videos. Every format is a wall between knowledge and your system.
MarkItDown tears down the wall.
It’s an open-source library built by Microsoft Research — a universal converter that my system wraps in 38 lines of Python. You give it any file. It gives you clean markdown. That’s it. That’s the whole pitch.
But “any file” means any file. PDFs. Word docs. Excel spreadsheets. PowerPoint decks with speaker notes. Images via OCR. Audio via speech-to-text. HTML pages stripped clean. Even EPUBs — full books, chapter by chapter. If it holds knowledge, MarkItDown converts it.
And then the extension that triggered this entire post: YouTube URLs.
Through the youtube-transcript-api — an open-source Python library that pulls transcripts directly from YouTube’s servers, no browser needed, no API key required — MarkItDown can now convert any YouTube video into a complete markdown document. Title, metadata, description, links, and the full transcript. No summary. No compression. Every word.
Think about that for a second. YouTube has over 800 million videos. Every lecture, every keynote, every podcast, every interview, every debate, every tutorial ever uploaded — all of it was locked behind a play button. You had to sit and watch. Or listen at 2x while half-paying attention. The knowledge was there, but it was trapped in a format your AI couldn’t touch. Or even worse, in a format that will take you a couple of lives to catch up.
The plug changes that. One line of Python, and any video becomes text your system can read, process, and integrate. MarkItDown doesn’t care if the source is a 12-page PDF or a 4-hour podcast. It converts the signal. It makes the connection. It plugs you in.
But a plug without a download is just a connection to nothing.
The download
This is where most tools stop. They convert a file, hand you the text, and call it done. You now have a very long markdown document and the same problem you had before: a pile of information with no home.
The download is different. The download is /ingest — and it was born from a single paragraph by Andrej Karpathy, the former head of AI at Tesla and one of the clearest thinkers in machine learning. He described something he called the “LLM Wiki”:
“Instead of just retrieving from raw documents at query time, the LLM incrementally builds and maintains a persistent wiki. When you add a new source, the LLM doesn’t just index it for later retrieval. It reads it, extracts the key information, and integrates it into the existing wiki — updating entity pages, revising topic summaries, noting where new data contradicts old claims.”
Read that slowly. Karpathy is naming the difference between two paradigms:
Retrieval — you store a document, and when someone asks a question later, you search for the relevant chunk and hand it to the AI. This is what most RAG systems do. The document sits there, untouched, waiting to be queried. It never talks to your other documents. It never changes what you already know.
Integration — the AI reads the source, understands it, and weaves it into the existing knowledge structure. It doesn’t just store the source. It metabolizes it.
That paragraph became the design spec for /ingest. The download works in five steps.
Step 1 — Receive. You give it anything: a file path, a URL, pasted text, even a vague reference like “ingest Karpathy’s LLM Wiki post.” The system routes by source type — articles go through web fetch, documents go through MarkItDown, YouTube URLs go through transcript extraction. Everything arrives as readable markdown.
Step 2 — Extract. The AI reads the full source and pulls out five layers:
Key claims — what does this source assert?
Entities — people, companies, products, concepts
Actions — anything I should do, consider, or follow up on
Connections — which existing vault files does this touch?
Contradictions — does anything here conflict with what I already know?
Step 3 — Discuss. Before touching a single file, the AI presents what it found and where it would file it. This is critical. A single source might want to update 12 files. I need to see the plan before it executes. The AI isn’t filing blindly — it’s proposing, and I’m confirming.
Step 4 — File. After I confirm: it writes the summary page, updates every connected project note, adds cross-references with wiki-links, flags contradictions with callout boxes, and updates the relevant indexes.
Step 5 — Log. It appends an entry to today’s daily note — source, destination, contradictions, action items — so the evening review captures what was ingested.
When I downloaded Acquired’s Google series, the system didn’t just file three transcripts and move on. It connected them to an existing note I’d written about Google’s provenance months earlier, flagged a venture strategy angle I hadn’t considered, and offered to update a project note with a new case study reference. One download, ripples everywhere.
Imagine.
A board member sends a 47-page PDF before a meeting? The plug converts it, the download metabolizes it. You walk in having not just read the document, but integrated it into everything you know about the business — with contradictions flagged against last quarter’s decisions.
Your competitor publishes a 2-hour keynote on YouTube? The plug transcribes it, the download maps every claim against your positioning docs. You don’t watch the video. You metabolize it.
Someone hands you a PowerPoint from a conference you missed? The plug converts every slide, the download connects the ideas to three project notes and surfaces a contradiction with your roadmap. Fifteen minutes of context that would have taken an afternoon.
The bookkeeping is the LLM’s job. That’s the Karpathy insight. The human decides what to ingest and what to do with the connections it surfaces. Everything else — the extraction, the filing, the cross-referencing, the contradiction detection — is AI.
Now, download without a brain is just data in transit.
The brain
Most people consume content. They listen to podcasts on walks. They read articles in the morning. They bookmark things “for later.” The information passes through them like food through someone who can’t digest it.
A few people take notes. They highlight passages, jot summaries in notebooks, maybe paste quotes into a note-taking app. This is better — but the notes sit in isolation. The insight from Tuesday’s podcast never meets the idea from last month’s book.
Almost nobody has a brain that metabolizes. Where the new source doesn’t just sit alongside existing knowledge — it changes it. Strengthens some connections, challenges others, creates new ones you hadn’t considered. The output isn’t a note. It’s a slightly different version of your entire understanding.
The vault is that brain.
A single download is powerful. But the real magic emerges when you’ve ingested 10, 20, 50 sources — because the brain starts surfacing connections you never made yourself. Cross-references are alive. They surface during morning planning. They appear in project reviews. They feed into the AI’s understanding of your patterns, your contradictions, your growth edges. The network compounds every day — not because you’re filing things manually, but because the system does the bookkeeping for you.
Let me share a brief story.
In 1895, a Belgian bibliographer named Paul Otlet attempted exactly this at a scale that would consume the rest of his life. He wanted to cross-reference all human knowledge using standardized index cards — one fact per card, linked by a decimal classification system. By the 1930s, he had 12 million cards in a building in Brussels called the Mundaneum. He even envisioned a “world network” where anyone could send a query by telegraph and receive answers compiled from the index. A search engine built on paper and wires, 60 years before the internet.
Mundaneum was gutted in 1940. Otlet died in 1944. Some people still think of him as a spiritual ancestor of the World Wide Web.
Otlet understood the fundamental truth: the bottleneck in knowledge work is not access to information. It’s integration. Connecting the new thing to everything you already know — that’s the work. That’s what took 12 million index cards, a building in Brussels, and a team of researchers working for decades.
Today: one plug, one download, one brain. 10.6 seconds.
This is the difference between knowing things and understanding things. Knowledge is static. Understanding is networked. And networks compound.
There is no spoon
The bottleneck was never the knowledge. It was never the format, the transcript, the file type, the play button. Every executive I talk to has the same problem — too many documents, too many meetings, too many videos they should have watched, too many decks they should have read. More information than anyone can metabolize alone.
That’s been the quiet constraint on every knowledge worker for decades. The bottleneck was the architecture between the source and your understanding.
Remove that, and the shape of the problem changes. You’re not drowning in content anymore. You’re curating what reaches the brain — and the brain does the bookkeeping. Your job shifts from reading everything to choosing what’s worth ingesting. From execution to judgment. From hoarding information to metabolizing it.
The pipeline is open-source. The converter is free. The /ingest command is a few lines and a disciplined prompt. None of this is expensive. None of it is locked behind an enterprise license.
What is scarce is the vault to ingest into — the accumulated context of who you are, what you’re building, what you already know, where to cross-reference. That’s the asset. That’s what compounds. The pipeline is the easy part; the brain you feed it into is the work.
Neo’s first words after the download were “I know kung fu.” But the line that mattered came later, when he looked at the world he’d been living in and finally saw it for what it was.
“There is no spoon.”
There’s no mountain of unread PDFs. No backlog of podcasts. No pile of slide decks waiting for a free afternoon. No ocean of video demanding lifetimes I don’t have. There’s just signal — and a brain that knows what to do with it.
That’s why I cried. One life just became enough.
I know kung fu. And now, so can my AI.
If you want to build your own AI Operating System with commands like /ingest, start with The File That Changes Everything — one file that turns your AI from a stranger into a partner.