
Attention, Made Simple
The one equation to understand every AI system you use
On my last post I showed you my AI metabolizing 12 hours of video into deeply integrated knowledge — in 10.6 seconds. That post answers a what question. The answer was one word: markdown.
As a researcher at heart — and with a PhD in AI in my background — I wanted to understand the wiring underneath the magic, and make it as simple as I could for myself and everyone reading. This post is the how (and the why) every AI feels so powerful these days.
Within hours of that metabolizing moment, the same question kept surfacing: okay, but how does the AI actually read it? A 154,526-token transcript isn’t just stored — it’s understood in one pass, cross-referenced against everything else, answered in seconds. What’s the mechanism?
If the what was markdown, the how has a single-word answer: attention.
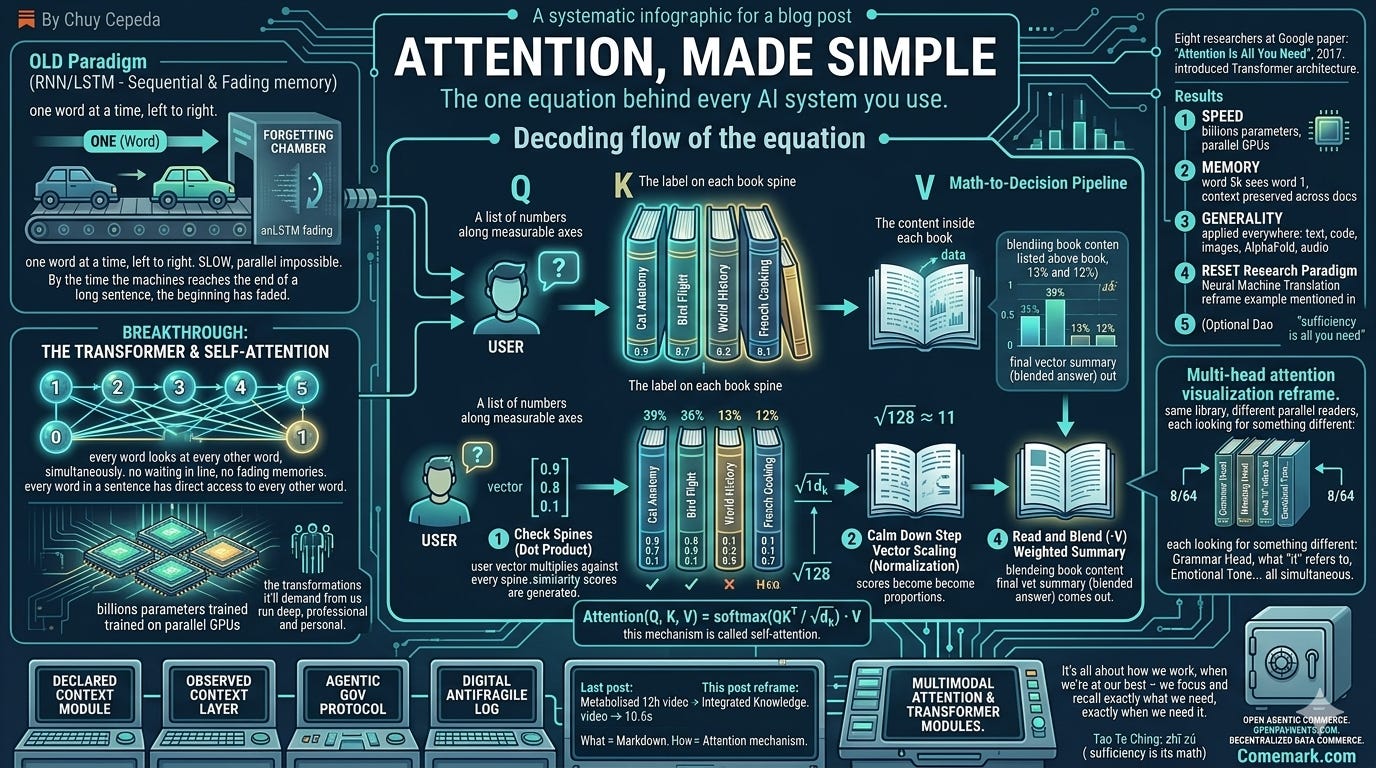
Every AI system in daily use — Claude, GPT, Gemini — descends from one 2017 paper by eight researchers at Google. It’s called Attention Is All You Need, and it introduced an architecture called the Transformer. The equation is famous. It’s also simpler than its reputation.
The transformations it’ll demand from us run deep, professional and personal.
The problem
Before 2017, if you wanted a machine to work with language — translate a sentence, predict the next word, generate text — you used an RNN (Recurrent Neural Network). The machine read words one at a time, left to right, like a person reading a sentence while trying to remember the beginning.
Two problems broke this at scale.
It was slow. Reading one word at a time meant you couldn’t use the full power of modern GPUs. Like having a highway and only letting one car on at a time.
It forgot. By the time the machine reached the end of a long sentence, the beginning had faded. Improved versions (LSTMs) delayed the forgetting — they didn’t solve it.
These weren’t minor inconveniences. They were structural walls. You can’t build a machine that understands a paragraph — let alone a book — if it forgets the first sentence by the time it reaches the last.
The breakthrough
The Transformer replaced “read one word at a time” with something radical: every word looks at every other word, simultaneously.
No waiting in line. No fading memories. Every word in a sentence has instant, direct access to every other word. The model decides which connections matter — and it does it all in one step.
This mechanism is called self-attention. And it’s captured in one equation:
Attention(Q, K, V) = softmax(QKᵀ / √d_k) · VIntimidating at first glance. It isn’t. Let’s see what it actually does.
The library analogy
Imagine you walk into a library with a question. There are books on the shelf. You need to figure out which ones are relevant, how much time to spend on each, and walk out with a blended answer — with your deeply integrated knowledge.
Recall the elements in the equation:
Query (Q) — your question. What you walked in looking for.
Key (K) — the label on each book’s spine. What each book claims to be about.
Value (V) — the actual content inside each book.
You compare your question against every spine. The books whose labels match get most of your reading time. You blend what you read into a single summary — weighted by relevance.
And the rest of the equation? Simpler than it looks.
The little ᵀ is a transpose — a pivot so the keys (K) mathematically line up to multiply against the queries (Q) cleanly.
√d_k is a calm-down step. Each question (Q) and each book spine (K) is actually a vector — a list of numbers. The longer the list, the bigger the raw scores, so we divide by the square root of the length of the list so the next multiplication doesn’t blow up.
Softmax that’s a function that transforms all the raw scores into values between 0 and 1, so attention reads as proportions instead of raw numbers.
None of these three change the story. They just make the math behave.
And that’s about it. That’s the attention equation.
Now, in a Transformer, every word in a sentence is simultaneously a reader and a book. Every word asks its own question while also being available for every other word to read. The sentence attends to itself — hence self-attention. A way of reading that doesn’t try to read everything.
Walking through it
Let’s say you walk into the library with this question: “How do animals move?”
Four books on the shelf, their spines read as follows:
📗 Cat Anatomy — about feline muscles and reflexes
📘 World History — about wars and treaties
📙 Bird Flight — about wings, lift, and migration
📕 French Cooking — about sauces and technique
Here’s what happens, step by step.
Step 1 — Check the spines (QKᵀ)
Before the model can compare your question (Q) against each book’s label (K), it first turns them into vectors — lists of numbers along measurable axes. For our library example, let’s use three yes/no questions:
Is it about animals?
Is it about movement?
Is it about culture?
Each axis is scored from 0 (no) to 1 (very yes). Your question — “How do animals move?” — scores: animals? 0.9. Movement? 0.8. Culture? 0.1. So it becomes [0.9, 0.8, 0.1]. The four books on the shelf get the same treatment.
Now, to determine relevance (the attention it deserves), we use a dot product. A high score means “this book is about what I’m asking.”
Your question = [0.9, 0.8, 0.1] (very animal, very movement, not culture)
📗 Cat Anatomy = [0.9, 0.7, 0.1] → Score: 1.38 ← relevant
📘 World History = [0.1, 0.2, 0.9] → Score: 0.34 ← not relevant
📙 Bird Flight = [0.8, 0.9, 0.1] → Score: 1.45 ← most relevant
📕 French Cook = [0.1, 0.1, 0.7] → Score: 0.24 ← least relevantWhat a dot product is: take two lists of numbers, multiply each pair, add them up. The result tells you how similar the two lists are — how much they “point in the same direction.” High score = similar. Low score = different. That’s it.
Real LLMs don’t use 3 axes. They use 64 to 128 or more — abstract axes the model figures out for itself (one might capture tense, another emotional tone, another “animal-ness”). None of them are human-readable, but they work exactly the same way as our three yes/no sample questions.
Step 2 — Scale down (/ √d_k)
With those 64-128 axes, raw dot products get huge — the more numbers you multiply and sum, the bigger the total grows just by chance. Dividing by the square root of the vector’s length (√128 ≈ 11 in modern systems) keeps the numbers in a healthy range. A practical fix for numerical stability — nothing more.
Step 3 — Make a reading plan (softmax)
You have raw scores. You need a plan: what percentage of your time (attention) goes to each book? Softmax converts the scores into percentages that add to 100%.
Raw scores: [1.38, 0.34, 1.45, 0.24]
Reading plan: 📗 36% 📘 13% 📙 39% 📕 12%
Bird Flight wins the most time. Cat Anatomy is close behind. History and Cooking barely get a glance. Softmax amplifies differences — relevant books win, irrelevant ones get scraps.
The first time I saw softmax written out, I braced for something complicated. It’s the machine asking: given these relevance scores, how should I divide my attention? That’s how raw math becomes a decision.
Step 4 — Read and blend (· V)
Now you open the books and read them according to your plan. You take from each book in proportion to its weight.
Your notes = 39% of Bird Flight + 36% of Cat Anatomy + scraps of the restYou walked in with one question, checked every spine, built a reading plan, and walked out with a single blended summary — mostly about animal movement, because that’s what was relevant.
That’s one pass of attention. One reader, one question, one blended answer.
How this becomes an AI that writes
Scale the library. The shelf isn’t four books — it’s billions of documents, articles, conversations, codebases — the internet itself. And it’s not one reader walking in. It’s every word in the text, reading each other and scoring everyone’s relevance to everyone else, all walking in at the same time, each with their own question, each checking every spine simultaneously.
They don’t walk in alone either. Real Transformers use multi-head attention — 8 or 64 parallel readers, each looking for something different. One head learns grammar. Another learns meaning. Another tracks what “it” refers to. Another follows emotional tone. Same library, different questions, all at once. This is where an elegant equation meets the hardware that finally made it possible.
After training on this library for weeks across thousands of GPUs, the model has internalized how language works — how ideas connect, how arguments build, how stories unfold, how code follows logic. Not from rules. From billions of attention passes over real text.
Then the leap — from reading to writing.
When you ask AI to “write a chapter about bird migration,” the model generates one word at a time. For each new word, attention checks everything that came before — the prompt, every word it’s already written — in one step. Word 5,000 has direct access to word 1. It still knows the chapter is about migration. It still maintains the tone from the opening. It still tracks which species were mentioned three pages ago — and ignores everything that doesn’t matter.
Genius. Attention is all you need — the title meant it literally.
That’s how one equation for checking “book spines” became an architecture for writing books everything.
You could watch it ship
Here’s the part most stories skip: within two years of the paper, you could watch this change land in products hundreds of millions of people used every day.
Google Translate had spent a decade refining LSTM-based sequential translation. In late 2016 they shipped a Neural Machine Translation upgrade that made headlines for closing much of the gap to human quality — the high-water mark of the old paradigm.
Then the Transformer paper dropped, and Google quietly swapped attention-based architectures into product after product. Translators working with the output started filing the same observation on forums: the text had stopped reading like machine translation. Register preserved. Idioms handled. Long sentences that held together.
What changed wasn’t the dictionary or the data. It was that Word 5,000 could now see Word 1. The old system reached the end of long sentences and lost the thread. The new one didn’t. The same idea is now inside every multilingual surface you touch — Gmail’s Smart Compose in Spanish, WhatsApp’s live translation, the subtitles on half of YouTube.
A decade of research paradigm, reset in under two years. That’s what a platform shift looks like from the inside.
This is why thinkers like Yuval Noah Harari warn, with measured respect, that AI is a massive weapon. Because if anything transformed humanity, it was language — our capacity to build societies on shared narratives. And now there’s something artificial with an impressive attention span and near-infinite, fast-access memory — something that not only understands human language but also generates it (thus gen-AI).
Why this paper changed everything
Three things happened when self-attention replaced sequential processing.
Speed. All words processed simultaneously means every GPU core gets used. This is what enabled training models with billions of parameters — physically impossible with one-word-at-a-time RNNs.
Memory. Any word can attend to any other word in one step. Word 1 doesn’t fade by the time you reach word 10,000. Context is preserved across entire documents.
Generality. The same architecture — attention over sequences — works for text, code, images (Vision Transformers), audio, protein folding (AlphaFold), and more. One idea, applied everywhere.
Eight researchers at Google wrote this paper in 2017. Every major AI system in 2026 — GPT, Claude, Gemini, Llama — is a direct descendant.
The title said it all: attention is all you need.
Back to the library
Let me close where I started.
On my last post, my AI metabolized twelve hours of Acquired’s Google series into deeply integrated knowledge in just 10.6 seconds. The plug moved the text in. The download filed and cross-referenced it. But the actual reading — the thing that made the connections visible, that flagged the contradictions, that surfaced a note I’d written months ago and forgotten — that was billions of attention passes. Each one a tiny library walkthrough. Each one a question, a reading plan, a weighted summary.
It isn’t magic. It’s a library. It’s a question. It’s a reading plan. It’s a weighted summary, scaled to billions of “books”, sixty-four parallel readers, every word asking its own question at the same time. It’s math.
What happened to those eight researchers, and what Google did — and didn’t do — with their invention, is a different story. I wrote about the strategic story a few weeks back, in In an AI Rush, Sell Trust. This time, the mechanical one. Read one, you see the business of AI. Read both, you see the whole shape.
All that matters is this: it’s all about how we work, when we’re at our best — we focus and recall exactly what we need, exactly when we need it. The transformations it’ll demand from us — professional and personal — are an invitation to be there more often.
The equation is from 2017. The principle is much older — 知足 (zhī zú), the Tao Te Ching’s “knowing what is enough.” Attention is its math.
Attention is the mathematical instantiation of sufficiency
Pay sufficient attention.
Wonder why tech and the Dao in the same post? I’ve been “resurrecting” thinkers across these posts — ancient wisdom plus modern technology, the two things I love most. Take a look at the time I resurrected Jesus, the Philosopher.